MLOps - Explore ML tools
In the last post MLOPS - Lab Setup, I was able to set the local ML lab environment, and run validation in Jupyter Notebook to test the CODA device and performance on my local PC.
Although Jupyter Notebooks can be user-friendly tools for ML practice, offering easy interaction and immediate feedback, which simplifies testing and debugging, it has limitations such as reproducibility issues, challenges in collaboration and version control, scalability concerns for larger projects, and a lack of automation for tasks like retraining.
In this post, I will try an ML project with tools like DVC, MLflow, Docker, Apache Airflow, and CI/CD frameworks to strengthen machine learning workflows. This way can ensure reproducibility by tracking data and code versions, while MLflow logs metrics for effective experiment tracking. Although their initial setup can be complex and resource-intensive, these tools automate processes, streamline workflows, and enhance collaboration and scalability, which could be excessive for smaller ML projects.
ML Tools explained
- Data Versioning (DVC): DVC allows teams to manage and version datasets just like code. This ensures that data changes are tracked, making it easier to revert to previous versions if necessary.
- Experiment Tracking (MLflow): MLflow tracks experiments, capturing metrics, parameters, and model versions in one centralized location. This makes it easier to compare different runs and select the best-performing model.
- Containerization (Docker): Docker creates isolated environments, ensuring that code runs consistently across different platforms without dependency issues. This helps avoid the "it works on my machine" problem.
- Workflow Orchestration (Apache Airflow): Airflow schedules and manages complex workflows, allowing for the automation of tasks such as data retrieval, preprocessing, model training, and evaluation.
- CI/CD (Jenkins): I have a local Jenkins image to facilitate automatic testing and deployment of models and code changes. This ensures that new features or updates are quickly integrated without disrupting the existing workflow.
Combining these tools to achieve a holistic pipeline enables reproducibility, scalability, and consistency in machine learning workflows.
Project Structure
Create a new project directory with the following structure:
(jupyter_env) root@zackz:/mnt/mlops-project# tree mlops-project/ ├── data/ # Data directory (for DVC) ├── models/ # Trained models ├── src/ # Source code for the ML model ├── notebooks/ # Jupyter notebooks for experimentation ├── Dockerfile # Docker config for packaging ├── dvc.yaml # DVC pipeline config ├── airflow_dags/ # Airflow DAG for automation └── mlflow/ # MLflow tracking directory
Project Implementation
Step 1: Data Versioning with DVC
Initialize Git & DVC
pip install dvc git init dvc init -f
Add the Iris Dataset:
mkdir data curl -o data/iris.csv https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data dvc add data/iris.csv
Step 2: Train the Model (Using MLflow)
Install MLflow
pip install mlflow
Create a Training Script (src/train.py)
vim src/train.py
import mlflow
import mlflow.sklearn
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# Load the dataset
data = pd.read_csv('../data/iris.csv', header=None)
X = data.iloc[:, :-1]
y = data.iloc[:, -1]
# Split data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Track experiment with MLflow
with mlflow.start_run():
# Train model
model = RandomForestClassifier(n_estimators=100)
model.fit(X_train, y_train)
# Make predictions
predictions = model.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
# Log model and metrics to MLflow
mlflow.log_metric("accuracy", accuracy)
mlflow.sklearn.log_model(model, "model")
print(f"Model accuracy: {accuracy}")
Run the Training Script
python src/train.py (jupyter_env) root@zackz:/mnt/f/1/mlops-project# python src/train.py 2024/10/05 13:33:39 WARNING mlflow.models.model: Model logged without a signature and input example. Please set `input_example` parameter when logging the model to auto infer the model signature. Model accuracy: 1.0
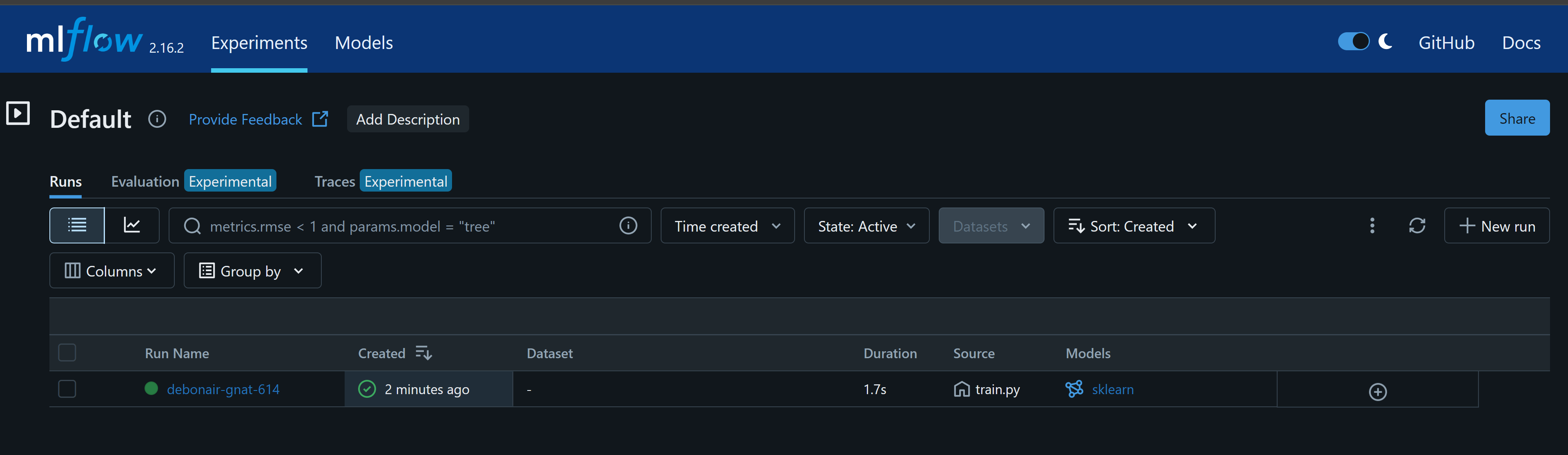
Launch the MLflow UI
mlflow ui
Navigate to http://127.0.0.1:5000 to view the experiment
Step 3: Dockerize the Model for Deployment
Create Dockerfile:
vim Dockerfile FROM python:3.8-slim WORKDIR /app # Install dependencies COPY requirements.txt . RUN pip install --no-cache-dir -r requirements.txt # Copy the source code COPY . . # Run the model training script CMD ["python", "src/train.py"]
Create a requirements.txt file and build the mlops-local-model Docker image:
vim requirements.txt mlflow scikit-learn pandas dvc docker build -t mlops-local-model . docker run mlops-local-model (jupyter_env) root@zackz:~# docker run mlops-local-model 2024/10/05 02:50:58 WARNING mlflow.utils.git_utils: Failed to import Git (the Git executable is probably not on your PATH), so Git SHA is not available. Error: Failed to initialize: Bad git executable. The git executable must be specified in one of the following ways: - be included in your $PATH - be set via $GIT_PYTHON_GIT_EXECUTABLE - explicitly set via git.refresh() All git commands will error until this is rectified. This initial message can be silenced or aggravated in the future by setting the $GIT_PYTHON_REFRESH environment variable. Use one of the following values: - quiet|q|silence|s|silent|none|n|0: for no message or exception - warn|w|warning|log|l|1: for a warning message (logging level CRITICAL, displayed by default) - error|e|exception|raise|r|2: for a raised exception Example: export GIT_PYTHON_REFRESH=quiet 2024/10/05 02:51:00 WARNING mlflow.models.model: Model logged without a signature and input example. Please set `input_example` parameter when logging the model to auto infer the model signature. Model accuracy: 1.0
Step 4: Automate with Apache Airflow
Install Apache Airflow:
pip install apache-airflow
Create an Airflow DAG (airflow_dags/ml_pipeline.py)
vim airflow_dags/ml_pipeline.py
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from datetime import datetime
import os
# Define the DAG
default_args = {
'owner': 'airflow',
'start_date': datetime(2023, 1, 1),
'retries': 1,
}
dag = DAG('mlops_pipeline', default_args=default_args, schedule_interval='@daily')
# Define the task to retrain the model
def retrain_model():
os.system('python src/train.py')
retrain_task = PythonOperator(
task_id='retrain_model',
python_callable=retrain_model,
dag=dag
)
retrain_task
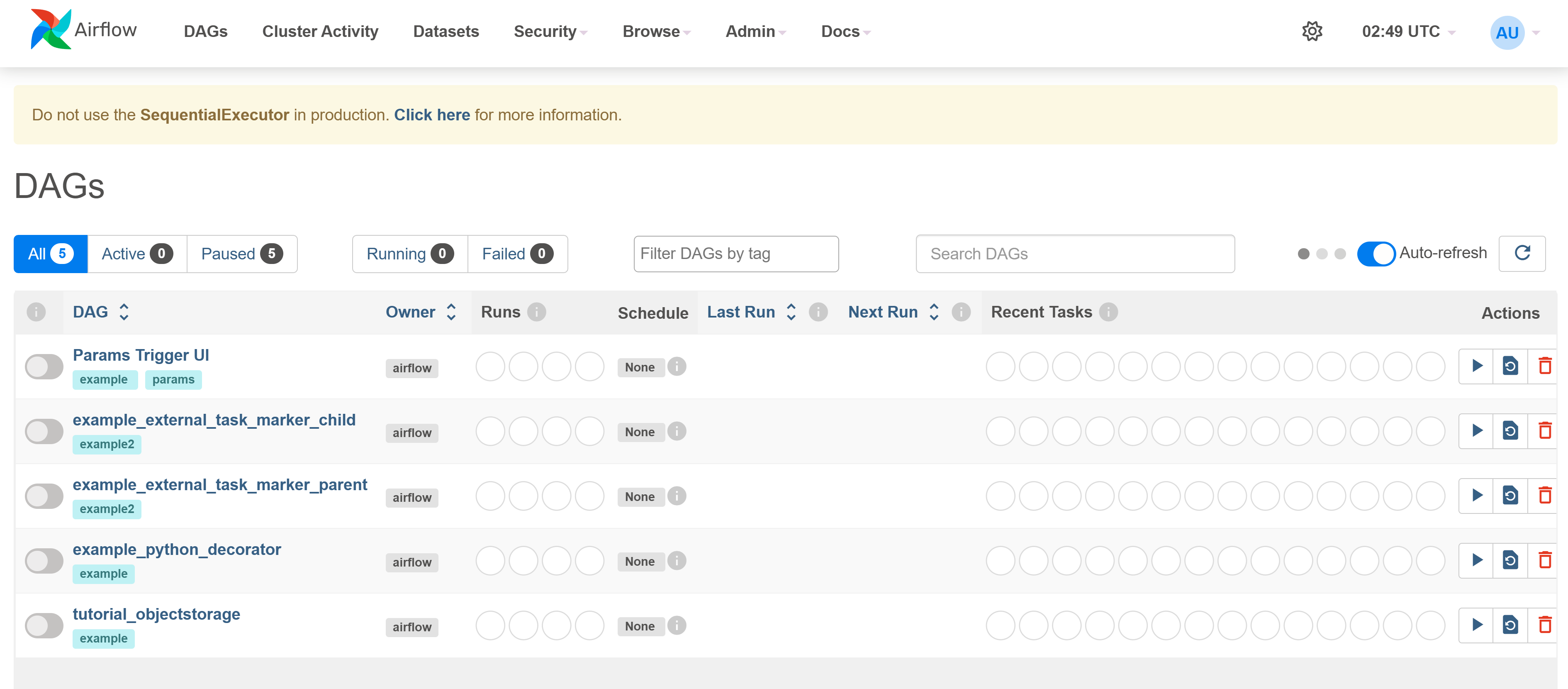
Run Airflow:
airflow db init airflow webserver --port 8080 airflow scheduler
Create Airflow web UI Admin user
airflow users create \ --username admin \ --firstname Admin \ --lastname User \ --role Admin \ --email [email protected] \ --password the_password
Navigate to http://127.0.0.1:8080 to view the Airflow
Step 5: CICD with Jenkins
Create Jenkins pipeline for continuous model training with the following stages:
Conclusion
By integrating DVC, MLflow, Docker, Airflow, and CI/CD into a cohesive ML project environment, we can achieve enhanced efficiency, greater automation, and improved collaboration. This synergy not only streamlines the development process but also ensures that machine learning models are robust, reproducible, and ready for production deployment.
In summary, a production-level ML workflow integrates new data, automates model training and deployment, and continuously monitors model performance. By utilizing CI/CD pipelines, Docker for containerization, and tools for versioning and tracking, we can create a robust and efficient machine learning system that can adapt to changing data and business requirements.
In the next post, I will refactor the local tools into AWS ML services, to move the ML pipeline and deployment to the cloud.