
In the previous post I developed shell script + awscli to apply aws EC2 tags, since the last post we discovered Python Boto3 scripts for AWS resource automation and management, I think it is time to improve the EC2 tagging task with Python and boto3, together with file handling to achieve:
- List and export EC2 information to a CSV file (instanceID, default instance name, Existing tags)
- Define 4 mandatory tags in CSV header (Env, BizOwner, Technology, Project)
- Validate exported tags against the 4 mandatory new tags, if any of the new mandatory tags exists, then keep the tag and value, if any of the new mandatory tags do not exist, add the key and leave the value blank
- Get CSV file filled with mandatory tags input from Biz team (manual work)
- Open the updated CSV file, apply the mandatory tags based on the input value
- Create and trigger Lambda function with AWS config rules to enforce 4 mandatory tags whenever a new instance is launched
Here we need Python libraries for "boto3" and "csv", to call boto3 sessions to retrieve EC2 information, then use Python "with open" and "for" loops to write each EC2 info to a CSV file, also add mandatory tags write in the header fields "Env", "BizOwner", "Technology", "Project":
root@ubt-server:~/pythonwork/new# vim export1.py
# Import libraries
import boto3
import csv
# Define the mandatory tags
MANDATORY_TAGS = ["Env", "BizOwner", "Technology", "Project"]
# Initialize boto3 clients
ec2 = boto3.client('ec2')
def list_ec2_instances():
instances = []
response = ec2.describe_instances()
for reservation in response['Reservations']:
for instance in reservation['Instances']:
instance_id = instance['InstanceId']
default_name = next((tag['Value'] for tag in instance.get('Tags', []) if tag['Key'] == 'Name'), 'No Name')
tags = {tag['Key']: tag['Value'] for tag in instance.get('Tags', [])}
instance_info = {
'InstanceId': instance_id,
'DefaultName': default_name,
**tags
}
# Ensure mandatory tags are included with empty values if not present
for mandatory_tag in MANDATORY_TAGS:
if mandatory_tag not in instance_info:
instance_info[mandatory_tag] = ''
instances.append(instance_info)
return instances
# Define export to CSV
def export_to_csv(instances, filename='ec2_instances.csv'):
# Collect all possible tag keys
all_tags = set()
for instance in instances:
all_tags.update(instance.keys())
# Ensure mandatory tags are included in the header
all_tags.update(MANDATORY_TAGS)
fieldnames = ['InstanceId', 'DefaultName'] + sorted(all_tags - {'InstanceId', 'DefaultName'})
with open(filename, 'w', newline='') as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for instance in instances:
writer.writerow(instance)
def main():
instances = list_ec2_instances()
export_to_csv(instances)
print("CSV export complete. Please update the mandatory tags in 'ec2_instances.csv'.")
if __name__ == '__main__':
main()
root@ubt-server:~/pythonwork/new# python3 export1.py
CSV export complete. Please update the mandatory tags in 'ec2_instances.csv'.
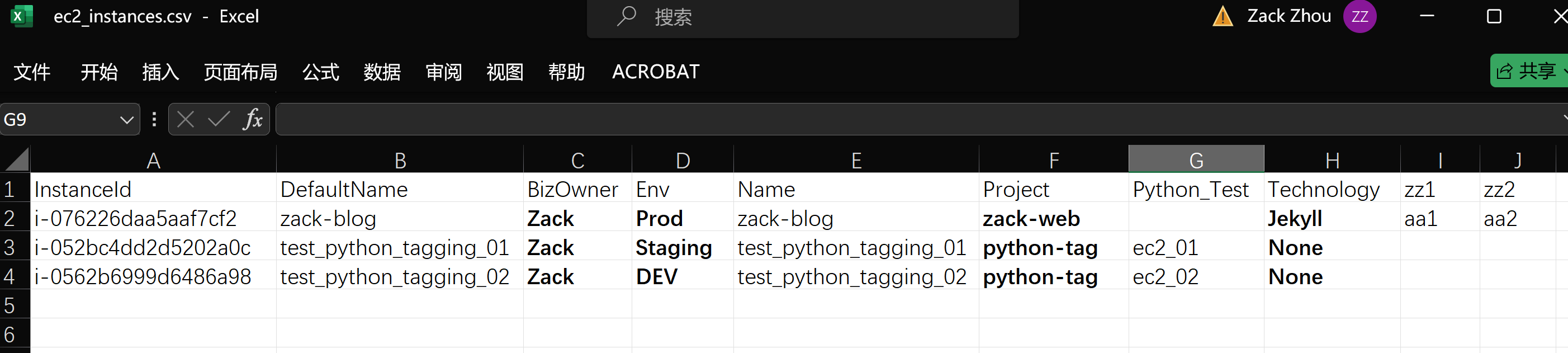
Next, download and update 'ec2_instances.csv' with all required tags, then rename and upload as 'ec2_instances_updated.csv', create second script "update1.py" to apply new tags:
root@ubt-server:~/pythonwork/new# vim update1.py
import boto3
import csv
# Define the mandatory tags
MANDATORY_TAGS = ["Env", "BizOwner", "Technology", "Project"]
def update_tags_from_csv(filename='ec2_instances_updated.csv'):
ec2 = boto3.client('ec2')
with open(filename, newline='') as csvfile:
reader = csv.DictReader(csvfile)
for row in reader:
instance_id = row['InstanceId']
tags = [{'Key': tag, 'Value': row[tag]} for tag in MANDATORY_TAGS if row[tag]]
if tags:
ec2.create_tags(Resources=[instance_id], Tags=tags)
def main():
update_tags_from_csv()
print("Tags updated successfully from 'ec2_instances_updated.csv'.")
if __name__ == '__main__':
main()
root@ubt-server:~/pythonwork/new# python3 update1.py
Tags updated successfully from 'ec2_instances_updated.csv'.
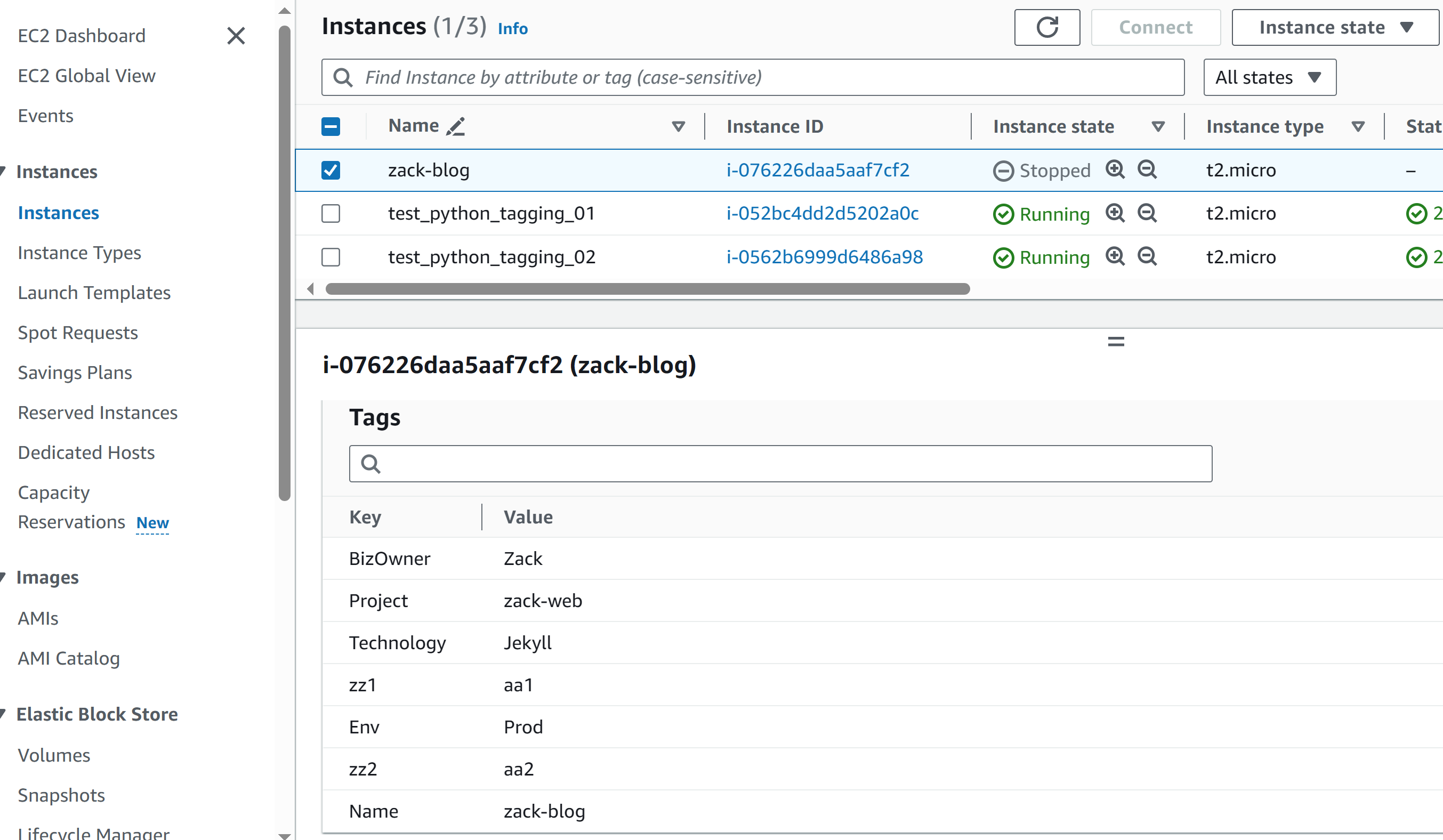 How about managing tags for multiple AWS accounts
How about managing tags for multiple AWS accounts
Considering we have 20+ AWS accounts across the company and with more than 200 EC2 instances that need to apply tagging strategy, here I will:
- Use AWS CLI profile to configure each AWS account creds, here I will use my own 2 AWS accounts (ZackBlog and JoeSite) to create AWS CLI profiles to validate the Python scripts
# Add account creds into ~/.aws/credentials vim ~/.aws/credentials [aws_account_zackblog] aws_access_key_id = xxxx aws_secret_access_key = yyyy [aws_account_joesite] aws_access_key_id = zzzz aws_secret_access_key = yyyy
# add profiles into ~/.aws/config vim ~/.aws/config [profile aws_account_zackblog] region = ap-southeast-2 [profile aws_account_joesite] region = ap-southeast-2
Now update Python scripts to call each account profile to apply all 20+ AWS accounts in sequence.
root@ubt-server:~/pythonwork# mkdir mutiple-aws
root@ubt-server:~/pythonwork# cd mutiple-aws/
root@ubt-server:~/pythonwork/mutiple-aws# vim export2.py
import boto3
import csv
from botocore.exceptions import ProfileNotFound
# Define the mandatory tags
MANDATORY_TAGS = ["Env", "BizOwner", "Technology", "Project"]
# List of AWS account profiles
AWS_PROFILES = ["aws_account_zackblog", "aws_account_joesite"] # Add more profiles as needed
def list_ec2_instances(profile_name):
session = boto3.Session(profile_name=profile_name)
ec2 = session.client('ec2')
instances = []
response = ec2.describe_instances()
for reservation in response['Reservations']:
for instance in reservation['Instances']:
instance_id = instance['InstanceId']
default_name = next((tag['Value'] for tag in instance.get('Tags', []) if tag['Key'] == 'Name'), 'No Name')
tags = {tag['Key']: tag['Value'] for tag in instance.get('Tags', [])}
instance_info = {
'InstanceId': instance_id,
'DefaultName': default_name,
**tags
}
# Ensure mandatory tags are included with empty values if not present
for mandatory_tag in MANDATORY_TAGS:
if mandatory_tag not in instance_info:
instance_info[mandatory_tag] = ''
instances.append(instance_info)
return instances
def export_to_csv(instances, profile_name):
filename = f"ec2_instances_{profile_name}.csv"
# Collect all possible tag keys
all_tags = set()
for instance in instances:
all_tags.update(instance.keys())
# Ensure mandatory tags are included in the header
all_tags.update(MANDATORY_TAGS)
fieldnames = ['InstanceId', 'DefaultName'] + sorted(all_tags - {'InstanceId', 'DefaultName'})
with open(filename, 'w', newline='') as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for instance in instances:
writer.writerow(instance)
def process_all_profiles():
for profile in AWS_PROFILES:
try:
print(f"Processing profile: {profile}")
instances = list_ec2_instances(profile)
export_to_csv(instances, profile)
print(f"CSV export complete for profile {profile}. Please update the mandatory tags in 'ec2_instances_{profile}.csv'.")
except ProfileNotFound:
print(f"Profile {profile} not found. Skipping.")
if __name__ == '__main__':
process_all_profiles()
Export 2 CSV files for each AWS account based on given profile, update mandatory tags in the 2 CSV files, then upload and rename as _updated_:
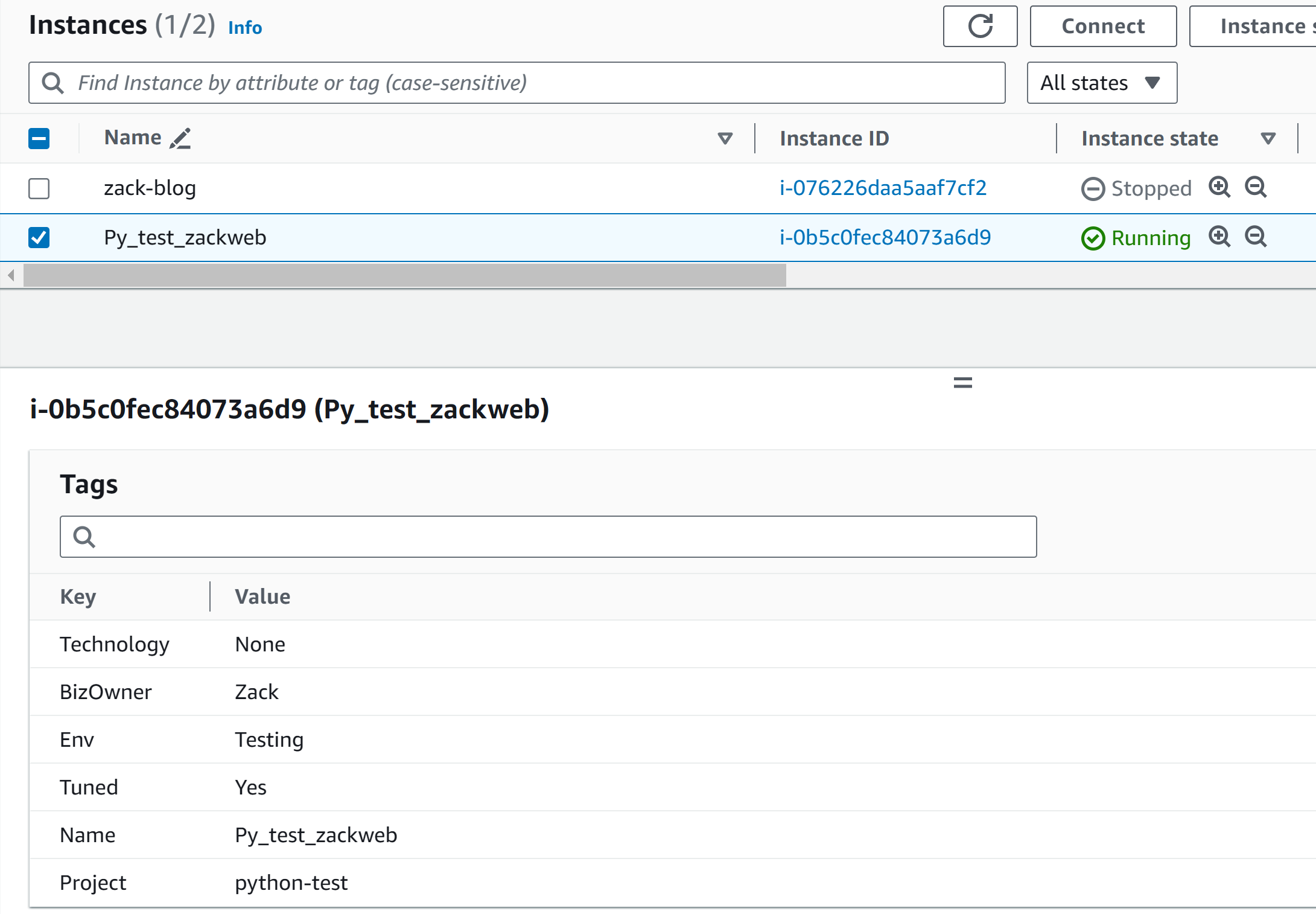
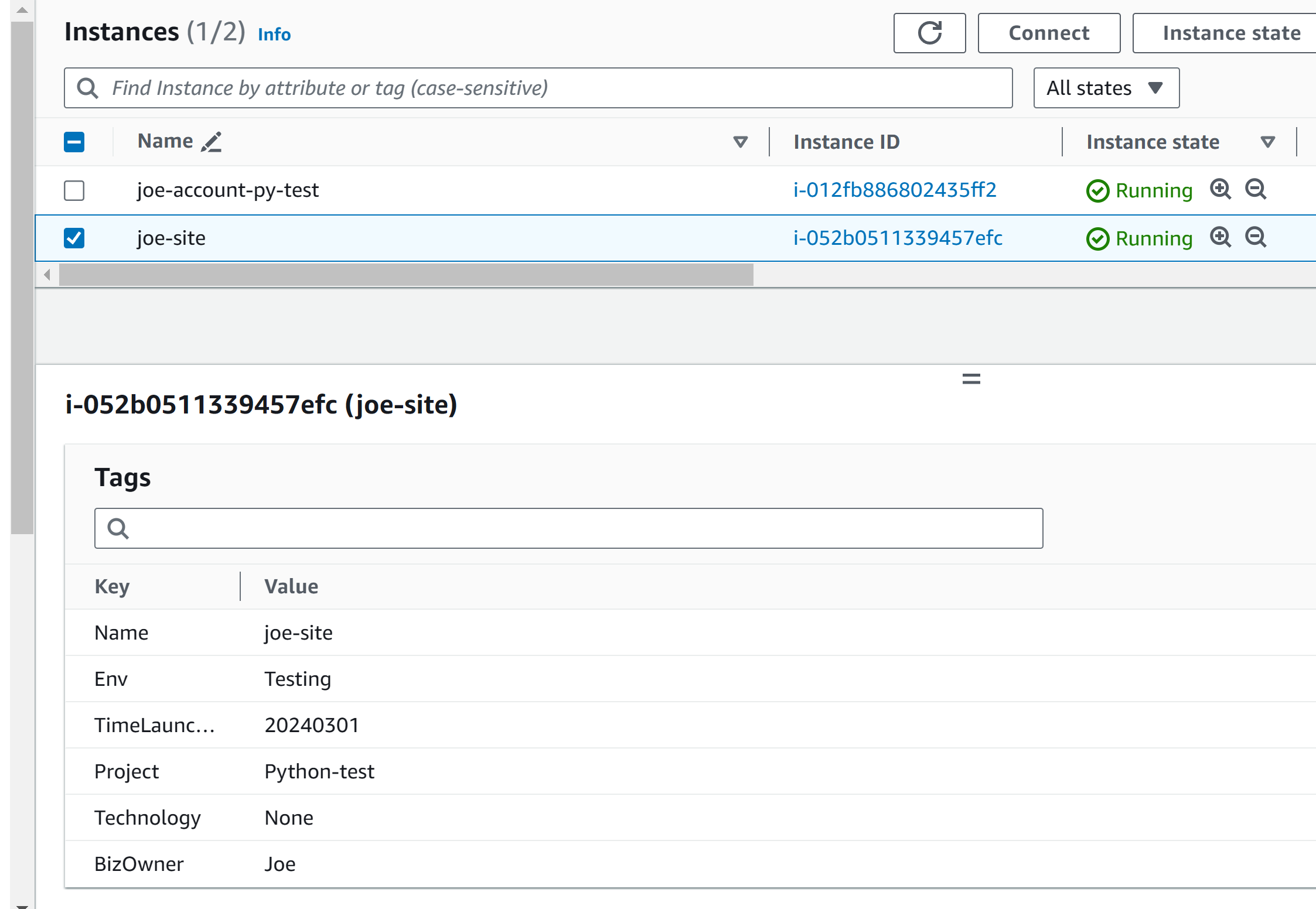
# export 2 csv files root@ubt-server:~/pythonwork/mutiple-aws# python3 export2.py Processing profile: aws_account_zackblog CSV export complete for profile aws_account_zackblog. Please update the mandatory tags in 'ec2_instances_aws_account_zackblog.csv'. Processing profile: aws_account_joesite CSV export complete for profile aws_account_joesite. Please update the mandatory tags in 'ec2_instances_aws_account_joesite.csv'. # update all mandatory tags in the files root@ubt-server:~/pythonwork/mutiple-aws# cat ec2_instances_updated_aws_account_zackblog.csv InstanceId,DefaultName,BizOwner,Env,Name,Project,Technology,Tuned,zz1,zz2 i-076226daa5aaf7cf2,zack-blog,Zack,Prod,zack-blog,zack-web,Jekyll,,aa1,aa2 i-0b5c0fec84073a6d9,Py_test_zackweb,Zack,Testing,Py_test_zackweb,python-test,None,Yes,, root@ubt-server:~/pythonwork/mutiple-aws# cat ec2_instances_updated_aws_account_joesite.csv InstanceId,DefaultName,BizOwner,Env,Location,Name,Project,Technology,TimeLaunched i-012fb886802435ff2,joe-account-py-test,Joe,Prod,SYD,joe-account-py-test,joesite,Ruby-Jekyll, i-052b0511339457efc,joe-site,Joe,Testing,,joe-site,Python-test,None,20240301
Now create python script "update_tags_2.py" to apply new tags for 2 AWS accounts by given profile:
import boto3
import csv
import re
# Define the mandatory tags
MANDATORY_TAGS = ["Tag1", "Tag2", "Tag3", "Tag4", "Tag5"]
# Initialize boto3 session for a given profile
def get_boto3_session(profile_name):
return boto3.Session(profile_name=profile_name)
# Fetch account ID using sts client
def get_account_id(session):
sts_client = session.client('sts')
return sts_client.get_caller_identity()['Account']
# Modified function to fetch and compare tags without applying changes
def check_tags_from_csv(session, filename, account_id, region):
ec2 = session.client('ec2')
rds = session.client('rds')
s3 = session.client('s3')
lambda_client = session.client('lambda')
elbv2 = session.client('elbv2')
efs = session.client('efs')
ecs = session.client('ecs')
with open(filename, newline='') as csvfile:
reader = csv.DictReader(csvfile)
for row in reader:
identifier = row.get('Identifier', '').strip()
service = row.get('Service', '').strip()
if not identifier or not service:
print(f"Skipping row due to missing 'Identifier' or 'Service': {row}")
continue
# Fetch current tags and identify missing mandatory tags
current_tags = fetch_existing_tags(service, identifier, session, account_id, region)
missing_tags = [tag for tag in MANDATORY_TAGS if tag not in [t['Key'] for t in current_tags]]
# Output resources missing mandatory tags
if missing_tags:
print(f"Resource: {identifier}, Service: {service}")
print(f"Current Tags: {current_tags}")
print(f"Missing Mandatory Tags: {missing_tags}\n")
# Function to fetch existing tags for a given resource
def fetch_existing_tags(service, identifier, session, account_id, region):
try:
if service == 'EC2':
ec2 = session.client('ec2')
response = ec2.describe_tags(Filters=[{'Name': 'resource-id', 'Values': [identifier]}])
return [{'Key': tag['Key'], 'Value': tag['Value']} for tag in response['Tags']]
elif service == 'RDS':
rds = session.client('rds')
arn = f'arn:aws:rds:{region}:{account_id}:db:{identifier}'
response = rds.list_tags_for_resource(ResourceName=arn)
return response.get('TagList', [])
elif service == 'RDScluster':
rds = session.client('rds')
arn = f'arn:aws:rds:{region}:{account_id}:cluster:{identifier}'
response = rds.list_tags_for_resource(ResourceName=arn)
return response.get('TagList', [])
elif service == 'S3':
s3 = session.client('s3')
response = s3.get_bucket_tagging(Bucket=identifier)
return response.get('TagSet', [])
elif service == 'Lambda':
lambda_client = session.client('lambda')
arn = f'arn:aws:lambda:{region}:{account_id}:function:{identifier}'
response = lambda_client.list_tags(Resource=arn)
return [{'Key': k, 'Value': v} for k, v in response.get('Tags', {}).items()]
elif service == 'ElasticLoadBalancingV2':
elbv2 = session.client('elbv2')
arn = get_elbv2_arn_by_arn(elbv2, identifier)
response = elbv2.describe_tags(ResourceArns=[arn])
return response['TagDescriptions'][0]['Tags'] if response['TagDescriptions'] else []
elif service == 'EFS':
efs = session.client('efs')
response = efs.describe_tags(FileSystemId=identifier)
return response.get('Tags', [])
elif service == 'ECS':
ecs = session.client('ecs')
arn = f'arn:aws:ecs:{region}:{account_id}:service/{identifier}'
response = ecs.list_tags_for_resource(resourceArn=arn)
return response.get('tags', [])
else:
print(f"Unsupported service type {service}, cannot fetch tags.")
return []
except Exception as e:
print(f"Error fetching tags for {service} {identifier}: {e}")
return []
def get_elbv2_arn_by_arn(elbv2_client, load_balancer_partial_name):
"""Retrieve the ARN for a given ALB by partial name."""
try:
response = elbv2_client.describe_load_balancers()
for lb in response['LoadBalancers']:
if load_balancer_partial_name in lb['LoadBalancerArn'] or load_balancer_partial_name in lb['LoadBalancerName']:
return lb['LoadBalancerArn']
print(f"No matching ALB found for {load_balancer_partial_name}")
return None
except Exception as e:
print(f"Error retrieving ARN for ALB {load_balancer_partial_name}: {e}")
return None
if __name__ == '__main__':
# Define the CSV files and AWS profiles
csv_files = {
'account1': 'account1.csv', # AWS profile and CSV for account 1 resources
'account2': 'account2.csv', # AWS profile and CSV for account 2 resources
#'mst': 'mst.csv', # AWS profile and CSV for mst account resources
#'itbs': 'itbs.csv', # AWS profile and CSV for itbs account resources
}
# Process each profile and its corresponding CSV
for profile, csv_file in csv_files.items():
print(f"Processing tags for AWS profile: {profile}")
# Get the session for the current profile
session = get_boto3_session(profile)
# Fetch the account ID and region for the session
account_id = get_account_id(session)
region = session.region_name or 'us-east-1' # Set default region if not found
print(f"Using account ID: {account_id}, Region: {region}")
# Check tags from the CSV without applying changes
check_tags_from_csv(session, csv_file, account_id, region)
print("Tag comparison operation completed for all profiles.")
Run the script to apply tags:
root@ubt-server:~/pythonwork/mutiple-aws# python3 update_tags_2.py Processing profile: aws_account_zackblog Tags updated successfully from 'ec2_instances_updated_aws_account_zackblog.csv' for profile aws_account_zackblog. Processing profile: aws_account_joesite Tags updated successfully from 'ec2_instances_updated_aws_account_joesite.csv' for profile aws_account_joesite.
Now double-check the tags for both accounts:
 Conclusion
Conclusion
Now we can use Python Boto3 and file handling to achieve multiple-aws account EC2 tagging. With Python "csv" library, functions like "csv.DictReader", "with open" and "csv.DictWriter" to open, update and export CSV file, Python also supports handling data in JSON format with dictionary.
In the next post I will see how to use Python Flask to redesign Zack's blog for Web application development.
====================
====================