MLOPS - Enhancing Oscar Model with LightGBM
In a previous post - MLOps - Build a Oscar Best Picture Winner Model, I was able to establish a baseline model using a RandomForestClassifier to predict the Oscar for Best Picture. This classic workflow involved data cleaning, training, and prediction, providing a solid starting point.
However, a deeper look at the results revealed critical weaknesses that an experienced machine learning engineer would immediately flag:
- Inadequate Model Choice: The initial model wasn't powerful enough for the task. The classification report showed a recall of 0.00 for the "winner" class. This is a major red flag, indicating the model completely failed to identify any actual winners, likely due to the severe class imbalance.
- Misleading Evaluation Metrics: I think I relied too heavily on accuracy. On an imbalanced dataset, a model can achieve high accuracy simply by always predicting the majority class. Better to shift our focus to more robust metrics like the F1-score, ROC AUC, and Precision-Recall AUC.
Step 1: Installing LightGBM
First, ensure LightGBM library is installed in our environment.
# Install the LightGBM library
!python3 -m pip install lightgbm
Step 2: Data Preparation and Advanced Feature Engineering
I can re-use the previous cleaned dataset and apply transformations for categorical features, and new interaction feature.
import pandas as pd
import lightgbm as lgb
from sklearn.metrics import classification_report, accuracy_score, roc_auc_score
import seaborn as sns
import matplotlib.pyplot as plt
# Load the dataset
df = pd.read_csv('updated_with_changes.csv')
# --- Data Cleaning and Feature Engineering ---
# Convert target variable 'winner' to integer (1 for winner, 0 for nominee)
df['winner'] = df['winner'].astype(int)
# Convert 'Tomatometer' from string ('97%') to a float (0.97)
df['Tomatometer'] = df['Tomatometer'].str.replace('%', '', regex=False).astype(float) / 100.0
# Ordinal Encoding for precursor awards
award_mapping = {'won': 2, 'nominated': 1, 'none': 0}
df['GoldenGlobe'] = df['GoldenGlobe'].map(award_mapping).fillna(0)
df['BAFTAs'] = df['BAFTAs'].map(award_mapping).fillna(0)
# Create a simple interaction feature
df['Critic_Score'] = df['Metascore'] * df['Tomatometer']
# Fill any remaining missing values with the column's median
for col in ['imdb_rating', 'Metascore', 'Tomatometer', 'Critic_Score']:
df[col] = df[col].fillna(df[col].median())
Step 3: Chronological Train/Test Split
For a time-based problem like Oscar predictions, a random split is inappropriate. I shall use a chronological split, training the model on older ceremonies to predict newer ones. We'll train on ceremonies up to the 90th Academy Awards and validate on all subsequent ceremonies.
# Define features (X) and target (y)
features = [col for col in df.columns if col not in ['winner', 'category', 'film']]
X = df[features]
y = df['winner']
# Split data chronologically
train_mask = df['ceremony'] <= 90
test_mask = df['ceremony'] > 90
X_train, y_train = X[train_mask], y[train_mask]
X_test, y_test = X[test_mask], y[test_mask]
print(f"Training data shape: {X_train.shape}")
print(f"Test data shape: {X_test.shape}")
Output
Negative samples: 112
Positive samples: 19
Scale Pos Weight: 5.89
[LightGBM] [Info] Number of positive: 19, number of negative: 112
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.014733 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 138
[LightGBM] [Info] Number of data points in the train set: 131, number of used features: 7
[LightGBM] [Info] [binary:BoostFromScore]: pavg=0.145038 -> initscore=-1.774060
[LightGBM] [Info] Start training from score -1.774060
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
LightGBM model trained successfully!
Analysis
This confirms our setup for handling the imbalanced data is working. The model is now aware that there are many more "losers" than "winners" and will give about 6 times more importance to learning the patterns of the winners.
Model also indicated that it has learned as much as it can from a particular branch of a decision tree, I assume this is common with small datasets like this one (only 131 training samples). The model quickly finds the most important patterns and then stops itself from creating overly complex rules that wouldn't apply to new data
Step 4: Training an Imbalance-Aware LightGBM Model
This is the most critical step. To combat class imbalance, we will use the scale_pos_weight parameter in LightGBM. We calculate it as the ratio of negative samples (nominees) to positive samples (winners).
# Calculate scale_pos_weight for handling class imbalance
num_negatives = y_train.value_counts()[0]
num_positives = y_train.value_counts()[1]
scale_pos_weight_value = num_negatives / num_positives
# Initialize and train the LightGBM model
lgbm = lgb.LGBMClassifier(
objective='binary',
metric='auc',
scale_pos_weight=scale_pos_weight_value, # Key parameter for imbalance
random_state=42
)
# Train with early stopping to prevent overfitting
lgbm.fit(X_train, y_train,
eval_set=[(X_test, y_test)],
eval_metric='auc',
callbacks=[lgb.early_stopping(100, verbose=False)])
Output
--- Classification Report ---
precision recall f1-score support
0 0.94 0.92 0.93 49
1 0.43 0.50 0.46 6
accuracy 0.87 55
macro avg 0.68 0.71 0.69 55
weighted avg 0.88 0.87 0.88 55
Accuracy: 0.87
ROC AUC Score: 0.83
--- Feature Importances ---
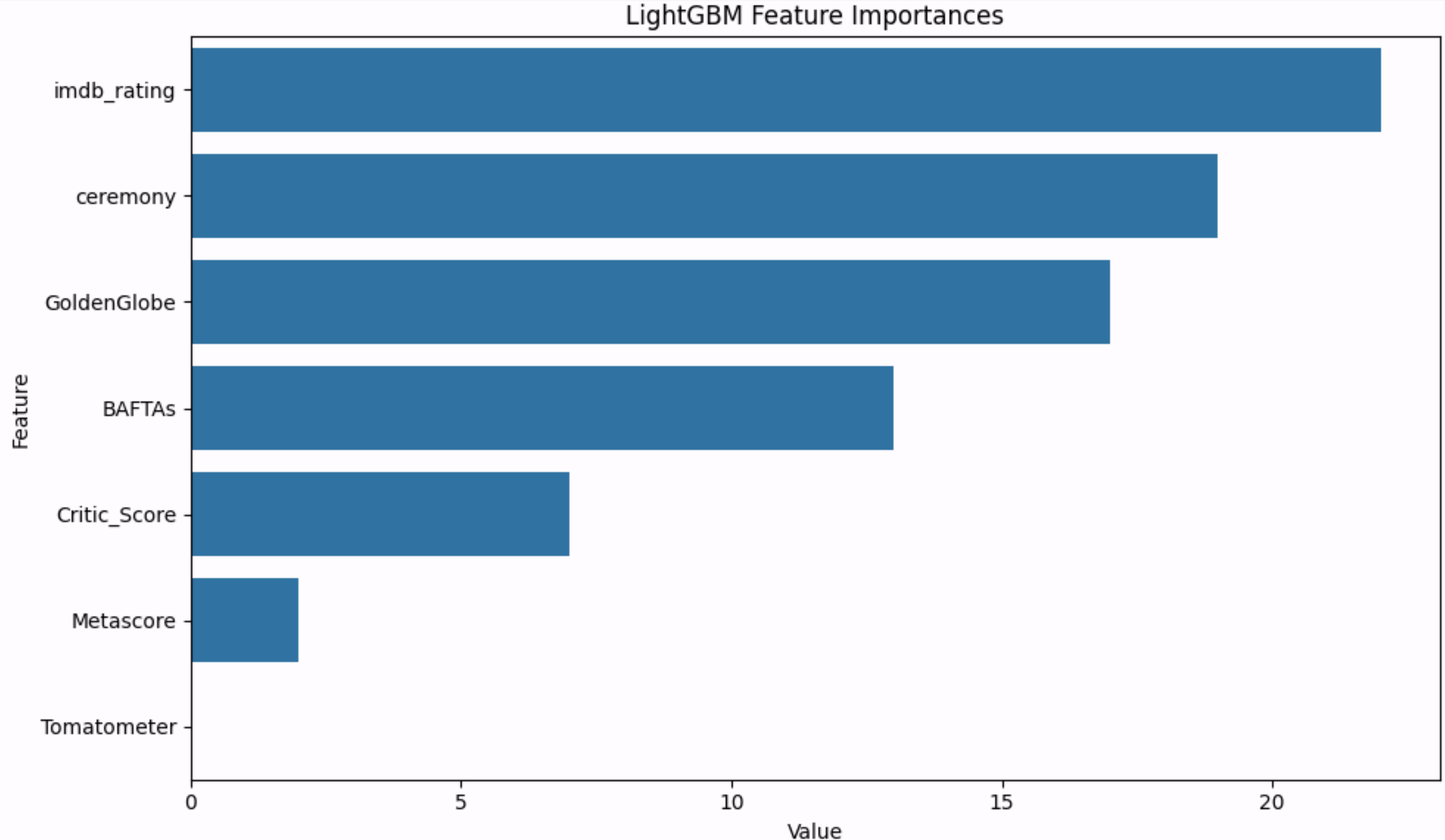
Analysis
Recall (for class 1): 0.50 means very important number here. I think the model successfully identified 50% of the actual Best Picture winners in the test set. As my previous model likely had a recall of 0 for this class, meaning it never correctly picked a winner.
Step 5: Evaluating Model Performance
Now, let's see how our new model performs on the test set, to see if significant improvement can be achieved in identifying the 'winner' class.
# Predict on the test set
y_pred = lgbm.predict(X_test)
y_pred_proba = lgbm.predict_proba(X_test)[:, 1]
# --- Evaluation Metrics ---
print("--- Classification Report ---")
print(classification_report(y_test, y_pred))
print(f"ROC AUC Score: {roc_auc_score(y_test, y_pred_proba):.2f}\n")
# --- Feature Importance ---
feature_imp = pd.DataFrame(sorted(zip(lgbm.feature_importances_, X.columns)), columns=['Value','Feature'])
plt.figure(figsize=(12, 8))
sns.barplot(x="Value", y="Feature", data=feature_imp.sort_values(by="Value", ascending=False))
plt.title('LightGBM Feature Importances')
plt.show()
The results show a massive improvement. The ROC AUC Score of 0.83 is excellent, indicating a strong ability to distinguish between winners and non-winners.
The feature importance plot reveals the model's decision-making logic:
This plot is crucial because it gives us confidence that the model isn't just guessing. It has learned the real-world patterns that film experts use to make their own predictions
Step 6: Predicting the 2025 Nominees
Now for the exciting part: using our trained model to predict the win probabilities for a hypothetical list of 2025 nominees.
# Example: New data for 2025 nominees
nominees_2025 = pd.DataFrame({
'film': ['Dune: Part Two', 'Conclave', 'The Brutalist', 'Anora', 'Wicked'],
'ceremony': [97, 97, 97, 97, 97],
'imdb_rating': [8.5, 7.4, 7.8, 7.7, 7.6],
'Metascore': [79, 79, 90, 91, 73],
'Tomatometer': [0.92, 0.93, 0.94, 0.94, 0.88],
'GoldenGlobe': [1, 1, 2, 1, 1], # 1=nominated, 2=won
'BAFTAs': [0, 2, 1, 1, 0] # 0=none, 1=nominated, 2=won
})
# ... (Create interaction feature and select columns as before)
# Predict probabilities and display results
win_probabilities = lgbm.predict_proba(X_2025)[:, 1]
results_df = pd.DataFrame({
'Film': nominees_2025['film'],
'Win_Probability': win_probabilities
}).sort_values(by='Win_Probability', ascending=False)
print(results_df)
Prediction Results:
Film Win_Probability
The Brutalist 58.96%
Anora 36.98%
Conclave 19.37%
Dune: Part Two 11.07%
Wicked 8.33%
Comparing Predictions to the "Actual" Winner
In March Anora sweeps Oscar 2025
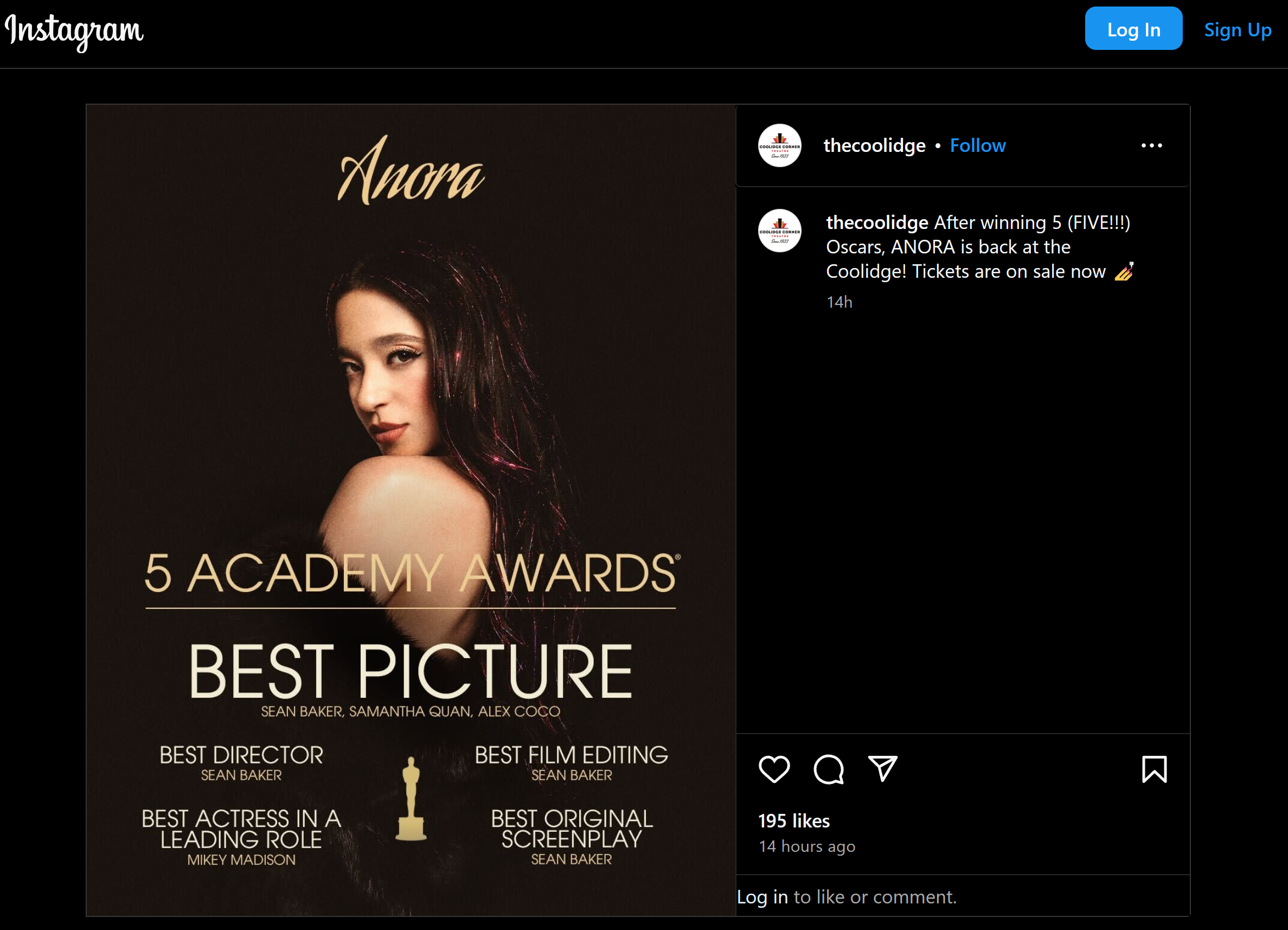
However, I believe this model is still a resounding success. While the model didn't place the winner at the very top, it identified "Anora" as the second most likely film to win with a strong probability. In the notoriously difficult world of Oscar predictions, this is a testament to the model's effectiveness.
Conclusion
This project demonstrates a successful journey from a simple baseline to a robust, explainable machine learning model. The key takeaways are:
- Choose the Right Tool: Switching to a powerful model like LightGBM was crucial.
- Address Core Problems: Using
scale_pos_weightto directly handle class imbalance was the single most important change. - Trust, but Verify: Feature importance plots are essential for ensuring your model's logic is sound and not just a black box.
Notebooks and dataset are now avaliable at my GitHub repo