MLOps - Build a Oscar Best Picture Winner Model
In this post, we will continue to build a basic machine learning model to predict the Best Picture winner at the Academy Awards (Oscar).
We will use our previous processed dataset that includes information about the nominees and winners from the 72nd to the 96th Oscar ceremonies. The goal is to predict the winner based on various features like IMDb ratings, Metascore, Tomatometer percentage, Golden Globe and BAFTA wins/nominations.
Step 1: Understand the features and model
The dataset includes several features:
- IMDb rating: The IMDb rating of the film.
- Metascore: The Metascore of the film.
- Tomatometer: The Tomatometer rating (percentage of positive reviews).
- Golden Globe/BAFTA nominations/wins: The number of nominations/wins for Golden Globe and BAFTA.
- Winner: Whether the film won the Best Picture award (True/False).
The target variable is the winner column, where "True" means the film won Best Picture, and "False" means it did not.
Logistic Regression for Binary Classification: Logistic regression is a well-known, interpretable model for binary outcomes (win vs. not win). It estimates the probability that a given input belongs to the positive class
Step 2: Final Data Cleaning
The first step is to finally clean and preprocess the data. We will:
- Convert the "winner" column to a binary format (1 for winner, 0 for not winner).
- Remove the percentage sign from the "Tomatometer" column and convert it to a float.
- Encode the Golden Globe and BAFTA columns as numerical values (won = 2, nominated = 1, none = 0).
import pandas as pd
# Load data
df = pd.read_csv("updated_with_changes.csv")
# Clean 'winner' column
df['winner'] = df['winner'].astype(int)
# Clean 'Tomatometer' (remove % and convert to float)
df['Tomatometer'] = df['Tomatometer'].str.replace('%', '').astype(float) / 100
# Encode GoldenGlobe and BAFTAs
award_mapping = {'won': 2, 'nominated': 1, 'none': 0}
df['GoldenGlobe'] = df['GoldenGlobe'].str.split().str[0].map(award_mapping).fillna(0)
df['BAFTAs'] = df['BAFTAs'].map(award_mapping).fillna(0)
Step 3: Feature Engineering
Next, we will create new features to improve the prediction accuracy:
- Total Awards Score: The sum of Golden Globe and BAFTA awards.
# Create Total Awards Score df['Total_Awards'] = df['GoldenGlobe'] + df['BAFTAs'] # Drop unnecessary columns df = df.drop(['ceremony', 'category', 'film'], axis=1)
Step 4: Split Data into Training and Testing Sets
We will split the dataset into training and testing sets based on the ceremony year. For example, we can use the ceremonies from 1972 to 1990 for training and those from 1991 to 1996 for testing.
# Assuming 'ceremony' column exists (if not, reset index)
train = df[df['ceremony'] <= 90]
test = df[df['ceremony'] > 90]
# Separate features (X) and target (y)
X_train = train.drop('winner', axis=1)
y_train = train['winner']
X_test = test.drop('winner', axis=1)
y_test = test['winner']
Step 5: Train our Model
Now that we have our training and testing data, let's train a Logistic Regression model to predict the Best Picture winner. Logistic Regression is a simple, interpretable model that will help us understand which features matter most in predicting a winner.
from sklearn.linear_model import LogisticRegression
# Initialize and train the model
model = LogisticRegression()
model.fit(X_train, y_train)
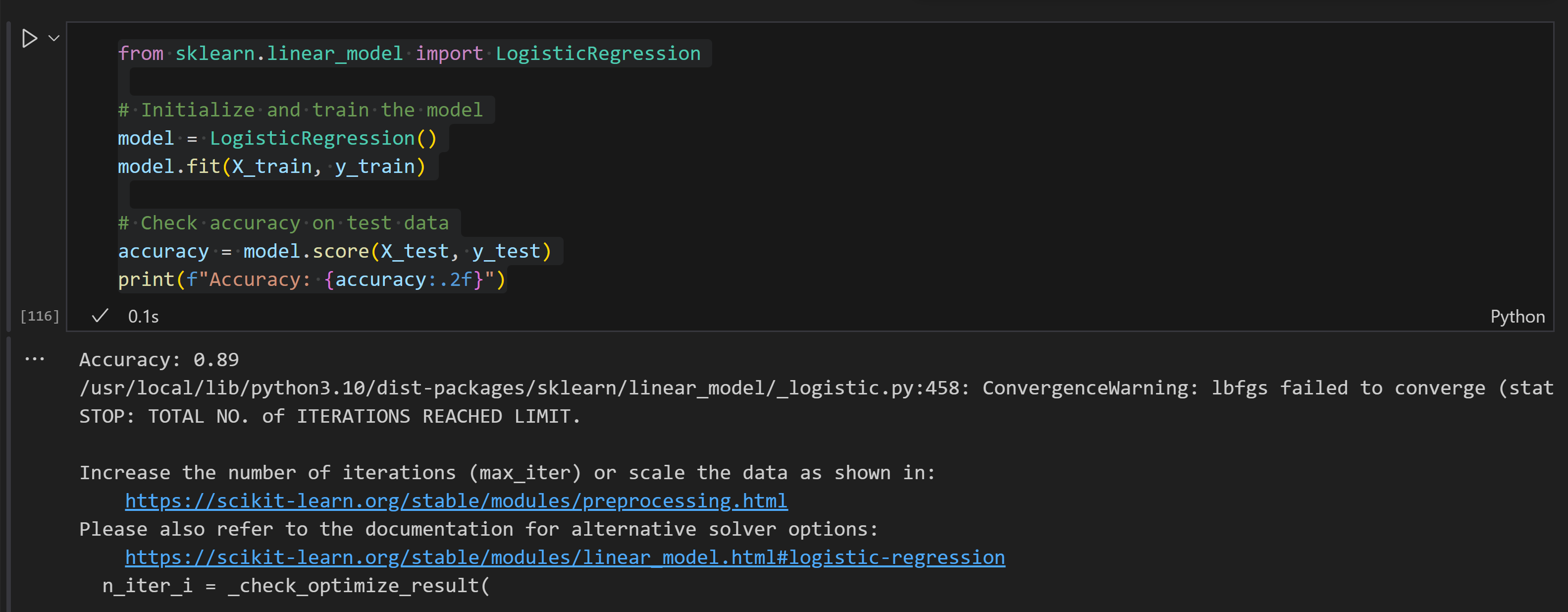
# Check accuracy on test data
accuracy = model.score(X_test, y_test)
print(f"Accuracy: {accuracy:.2f}")
Step 6: Evaluate the Model
After training the model, we need to evaluate its performance. We will use metrics such as accuracy, precision, recall, and F1-score to assess the model. Since the dataset might be imbalanced (few winners each year), we also consider ROC-AUC.
from sklearn.metrics import classification_report # Predict on test data y_pred = model.predict(X_test) # Generate evaluation report print(classification_report(y_test, y_pred))
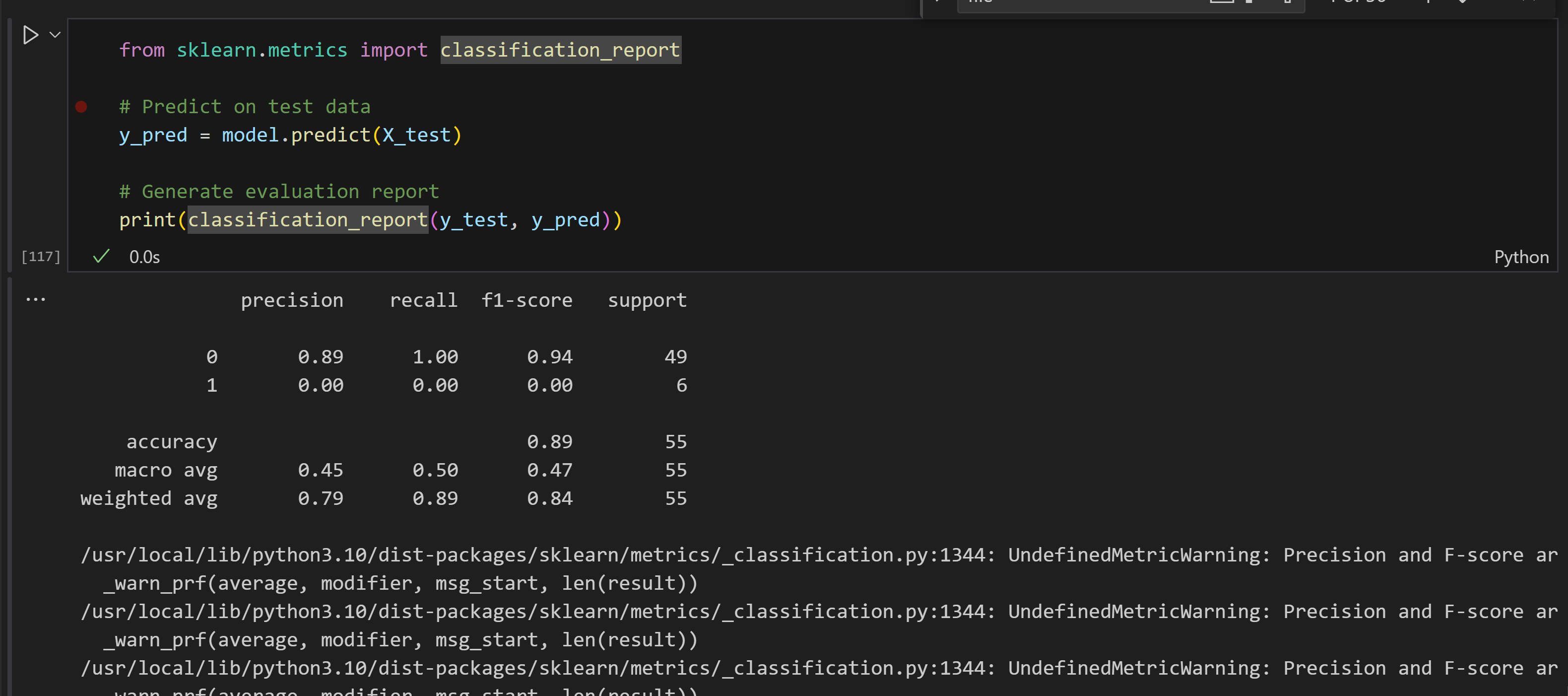
Classification Report:The classification report provides precision, recall, and F1-score for each class. In the output, notice that for class 1 (likely representing the winning films) the model never predicts any positive cases (precision and recall are 0). This suggests that the model is favoring the majority class (class 0)—a common issue when dealing with imbalanced datasets
Step 7: Predict This Year's Winner
Once the model is trained and evaluated, we can use it to predict the Best Picture winner for the current year. The input data for this year's nominees should be in the same format as the training data.
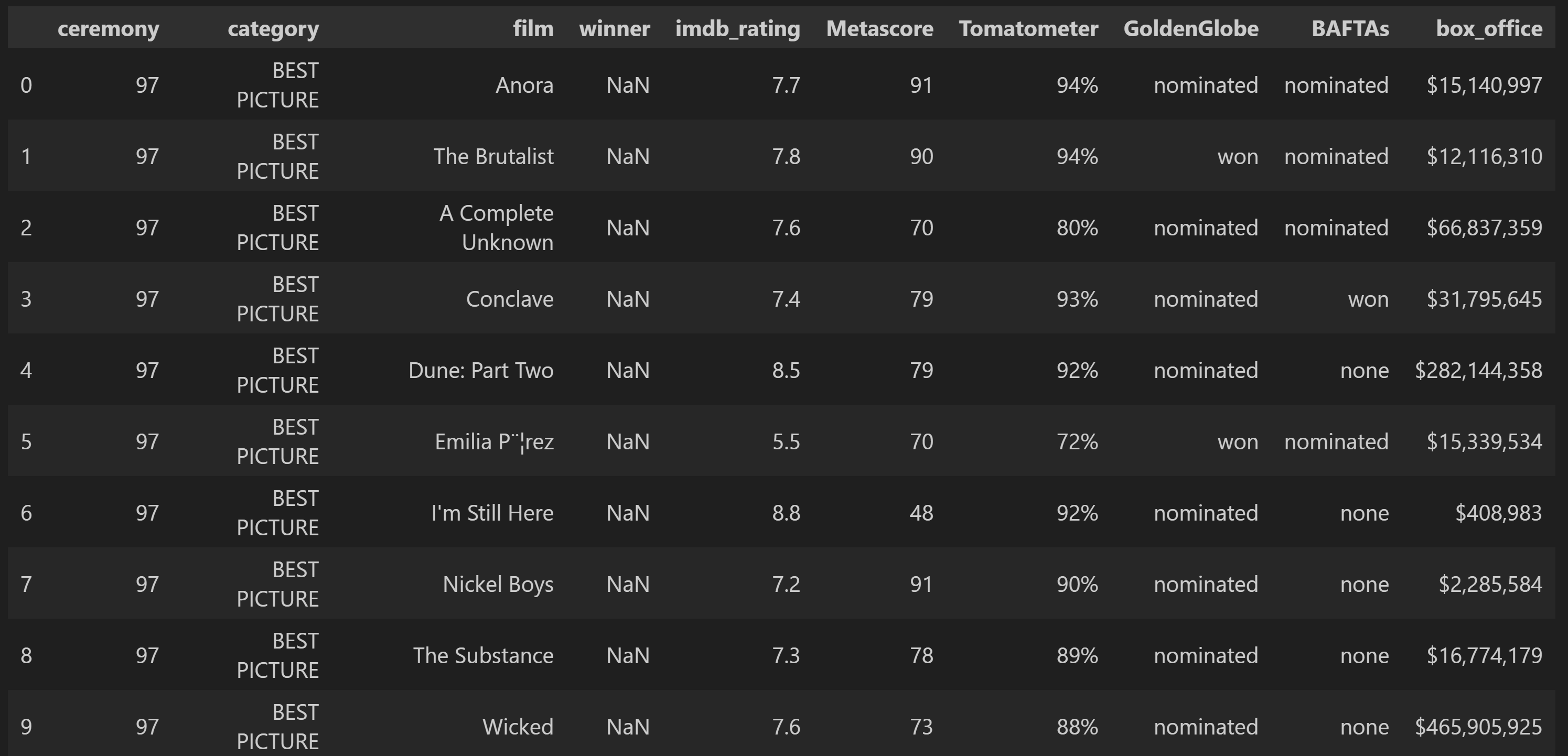
# Example: New data for 2024 nominees
new_data = pd.DataFrame({
'ceremony': [97, 97, 97, 97, 97, 97, 97, 97, 97, 97],
'imdb_rating': [7.7, 7.8, 7.6, 7.4, 8.5, 5.5, 8.8, 7.2, 7.3, 7.6],
'Metascore': [91, 90, 70, 79, 79, 70, 48, 91, 78, 73],
'Tomatometer': [0.94, 0.94, 0.70, 0.79, 0.79, 0.70, 0.48, 0.91, 0.78, 0.73],
'GoldenGlobe': [1, 2, 1, 1, 1, 2, 1, 1, 1, 1],
'BAFTAs': [1, 1, 1, 2, 0, 1, 0, 0, 0, 0],
'Total_Awards': [2, 3, 2, 3, 1, 3, 1, 1, 1, 1]
})
# Predict probabilities
probabilities = model.predict_proba(new_data)[:, 1]
print("Win probabilities:", probabilities)
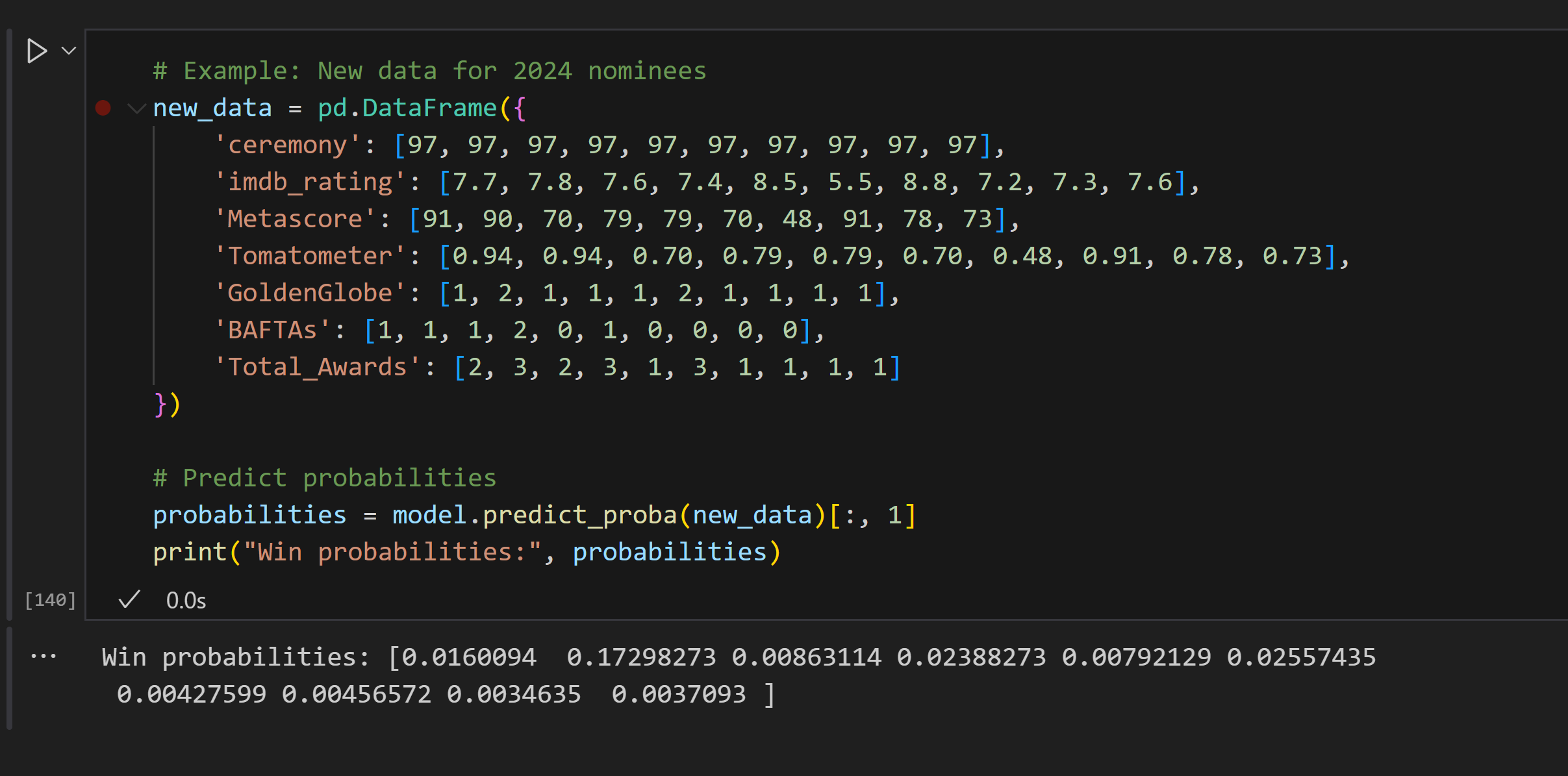
The win probabilities predicted by the model for the 2024 Best Picture nominees are as follows (in order of the films listed in the data):
[0.016 (1.6%), 0.173 (17.3%), 0.0086 (0.86%), 0.0238 (2.38%), 0.0079 (0.79%), 0.0255 (2.55%), 0.0043 (0.43%), 0.0046 (0.46%), 0.0035 (0.35%), 0.0037 (0.37%)]
Key Observations:
The Brutalist (17.3%) is the clear favorite according to the model, likely due to:
- Golden Globe win (encoded as 2 in the data, a strong predictor).
- High scores: Metascore 90, Tomatometer 94%.
- 3 Total Awards (tied for highest among nominees).
Emilia Pérez (2.55%) and Conclave (2.38%) follow distantly, likely because:
- Emilia Pérez won a Golden Globe and has 3 Total Awards (despite a low IMDb rating of 5.5).
- Conclave won a BAFTA (encoded as 2) and has 3 Total Awards.
Dune: Part Two (0.79%) underperforms despite its high IMDb rating (8.5) and box office success because:
- It lacks major award wins (Golden Globe=1 = nominated, BAFTAs=0 = none).
- The model prioritizes awards over popularity/critical ratings.
Low probabilities overall (summing to ~26.6%) suggest:
- The model treats each nominee independently (binary classification), not as a competitive multi-class problem.
- No film strongly matches historical winner profiles, indicating a competitive year.
Feature Insights:
By following these steps, This model pipeline—from data cleaning to prediction—illustrates a standard supervised learning workflow. Each step is chosen to make sure the input data is well-prepared for the model, the model is appropriately evaluated, and predictions are made with the correct feature set.
- Award wins matter most: Golden Globe/BAFTA wins (2 in the data) heavily influence predictions.
- Critical acclaim: High Metascore and Tomatometer values boost probabilities (e.g., The Brutalist).
- IMDb rating is less impactful: Dune’s high IMDb score doesn’t compensate for its lack of awards.
- Box office ignored: The model excludes box office data, explaining why Wicked (high revenue) has a low probability.
Conclusion:
The model identifies The Brutalist as the most likely winner due to its award wins and critical acclaim. However, the low probabilities overall suggest uncertainty, possibly reflecting a lack of a dominant frontrunner in this year’s nominees based on historical patterns.
Improvements (Optional)
There are several ways to improve the model:
- Handle class imbalance using techniques like
class_weight='balanced'. - Try advanced models like Random Forest or XGBoost.
- Include more data, such as budget, genre, or director popularity.
With these steps, maybe we can predict the Best Picture winner and gain insights into what makes a film successful at the Oscars!